Как устроен Яндекс?Эта информация взята с официального сайта Яндекса, для тех кому интересно, но не получалось найтина самом Яндексе :) Итак ... Крупные поисковые системы имеют базу размером в десятки миллионов документов и ежедневно обрабатывают миллионы пользовательских запросов, причём с каждым месяцем (с ростом количества пользователей интернета) эти цифры ощутимо увеличиваются. Например, если в начале лета 2001 года поисковая машина 'Яндекс' ежедневно отвечала на миллион запросов, то в 2002 году количество запросов удвоилось. В этих жёстких условиях главная задача поисковых систем - сохранение приемлемых для пользователей скорости и полноты выполнения запросов. Для запроса средней 'тяжести', то есть при поиске не очень частотного слова, время отклика системы (без учёта времени передачи данных по каналу от поисковой системы к пользовательскому компьютеру) должно исчисляться десятыми долями секунды. На сегодняшний день известны три основных подхода к решению этой проблемы:
Оптимизация поисковых алгоритмов и архитектуры поиска - это предмет постоянного внимания разработчиков. На Яндексе это делается пару раз в год и даёт в среднем процентов 20-30 уменьшения нагрузки и/или уменьшения времени отклика. Увеличение мощностей - это прямая 'гонка вооружения', то есть регулярный переход на более мощные процессоры, добавление оперативной памяти, увеличение объёма жёстких дисков. Несмотря на то, что тактовая частота процессоров увеличивается каждый месяц, новая техника 'не успевает' за ростом потребностей пользователей. К тому же постоянный апгрейд оборудования весьма недешев. Поэтому наряду с этим подходом используется масштабируемость архитектуры. Как устроен Яндекс
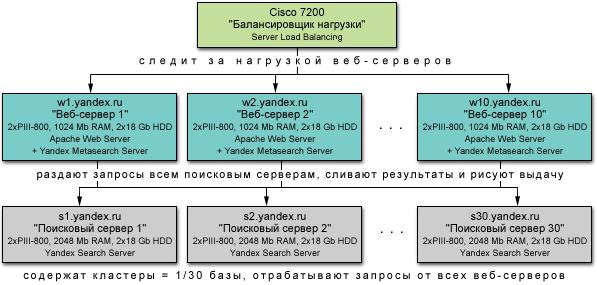
Рассмотрим параллельные решения на всех уровнях для архитектуры поисковой системы 'Яндекс'. Все количественные данные приводятся по состоянию на 5 марта 2002 года. A. Верхний уровень – уровень поискового веб-сервераРаспределение нагрузки между фронтальными веб-серверами выполняют Cisco - сетевые устройства балансировки нагрузки (www.cisco.com). Каждый пользователь в зависимости от своего IP-адреса (и/или cookies) перенаправляется на наименее загруженный веб-сервер из 10, используемых в поиске Яндекса. Заметим, что функционально фронтальные веб-серверы совмещены с модулями слияния поисковых результатов от веба и остальных поисковых источников (см. ниже). B. Средний уровень – уровень поисковой системыЕсли применить к поиск Яндексе традиционные термины Distributed Information Retrieval, то можно выделить следующие приемы распараллеливания. B.1. Разделение коллекции документов Начиная с весны 2000 года, в Яндексе используется 'параллельный поиск' в нескольких поисковых источниках. Параллельный поиск - это одновременный поиск в специализированных базах (коллекциях), предлагаемых поисковой системой. Обычно, источник - это отдельная база небольшого размера, отличная от 'большой' базы документов. Подразумевается, что документы, индексируемые в такой базе, имеют некоторую регулярную структуру. Если при поиске по обычной базе находятся и документы из базы параллельного поиска, точно соответствующие запросу, то одновременно (параллельно) с обычным результатами поиска выдаётся список из нескольких найденных документов. База параллельных источников имеет существенно меньший размер, чем база web-поиска. Обход и индексация документов в ней осуществляется отдельным роботом, поэтому обновление базы может происходить очень быстро (вплоть до ежеминутного). В 'Яндексе' есть четыре базы параллельного поиска:
Особый интерес с точки зрения традиционных поисковых технологий представляет техника разделения большой базы документов, то есть собственно базы веб-страниц. Сейчас (2002 год) она состоит из 60 млн. документов и разделена на 30 частей. Среди особенностей текущей реализации разделения веб-коллекции в Яндексе можно отметить следующее:
B.2 Первая фаза обработки запроса. Выбор коллекции. Трансформации запроса Пользователь может явно указать, в какой коллекции следует искать. Если этого не сделано, то на основе лингвистического (точнее, эвристического) анализа запроса Яндекс может сделать допущение о приоритете специализированной коллекции или подходящей к характеру запроса рубрики каталога. B.3 Вторая фаза обработки запроса. Раздача запроса по коллекциям Обычно используются все коллекции. Собирающий сервер раздает в коллекции модифицированные запросы, в которых для каждого термина сообщается глобальное значение его обратной частоты (IDF в терминах традиционного IR). Для этого на всех 'собирающих' серверах хранится глобальная статистика терминов. Она изменяется медленно, поэтому обновляется относительно редко. Статистика подсчитывается по считающейся наиболее универсальной - вебовской - коллекции. Таким образом, каждая поисковая машина ищет ответ на запрос с назначенными 'сверху' глобальными частотами, и значения релевантности, вычисляемые в разных коллекциях, можно считать последовательными и вычисляемыми 'в одной системе координат'. Модификации запросов этим не ограничиваются, и для специализированных коллекций (например, 'энциклопедии') могут быть и другими, в том числе и очень специфическими. B.4 Третья фаза обработки запроса. Исполнение и ранжирование запроса в коллекциях Запрос выполняется паралельно для всех коллекций: Следует отметить, что не веб-коллекции документов распределены по машинам произвольно и, вообще говоря, могут быть расположены все вместе на 1 машине. Слияние результатов производится на том из собирающих (метапоисковых) веб-сервере, на которую попадал пользователь при заходе по адресу www.yandex.ru. Процесс раздачи запроса, описанный в B.3, позволяет корректно ранжировать слитый результат. При этом не требуется переранжирование результатов, полученных из разных неоднородных коллекций с использованием локальных IDF, а также не нужен динамический обмен данными между источниками для вычисления глобальной IDF. C. Нижний уровень – уровень компьютераМашины поисковой системы 'Яндекс' работают на PC-серии процессоров (Pentium II, III, IV) компании Intel. На многих поисковых компьютерах установлено по 2 процессора (в терминологии распределенных вычислений - MIMD-архитектура). Диски, в большинстве случаев, организованы в технике striping (подвид RAID), то есть несколько физических устройств объединены в одно логическое, что позволяет распараллеливать процессы чтения и записи данных. Источник: prime-seo.com |
КОНТАКТЫ
г. Екатеринбург info@vismech.ru |
|
текущее: НОВОСТИ 05.12.2013 - Уход за флэш-накопителем 05.12.2013 - Компьютер самопроизвольно выключается 05.12.2013 - Почему не запускается компьютер? 27.11.2013 - Canon Legria HF R406 - Описание видеокамеры 27.11.2013 - TravelMate P645 новый лэптоп бизнес-класса от Acer |
|